GO-ITS 38 enterprise Problem Management process
This document establishes the enterprise Problem Management Principles, Roles and the associated process model. These standard elements provide a single unified process for enterprise Problem Management within the Ontario Public Service.
1. Foreword
Government of Ontario Information Technology Standards (GO-ITS) are the official publications on the IT standards adopted through the Office of the Corporate Chief Information Officer (OCCIO) and IT Executive Leadership Council (ITELC) for use across the government’s information and information technology (I&IT ) infrastructure.
These publications support the responsibilities of the Treasury Board Secretariat for coordinating standardization of I&IT in the Government of Ontario. In particular, GO IT Standards describe where the application of an IT standard is mandatory and specify any qualifications governing the implementation of the IT standards.
Applicability
All Ministries and I&IT clusters are subject to GO IT Standards.
All advisory and adjudicative agencies are subject to GO IT Standards. For the purposes of this document, any reference to Ministries or the Government includes applicable agencies.
All other agencies that are using Ontario Public Service (OPS) information and information technology products or services are required to comply with GO IT Standards if they are subject to either the management and use of I&IT directive or GO IT Standards by memorandum of understanding.
As new GO IT Standards are approved, they are deemed mandatory on a go-forward basis meaning at the next available project development or procurement opportunity as applicable.
When implementing or adopting any GO IT Standards, Ministries, I&IT clusters and applicable agencies must follow their organization’s pre-approved policies and practices for relevance of this standard and ensuring that adequate change control, change management and risk mitigation mechanisms are in place and employed.
2. Introduction
Background
The Government of Ontario Standard for Problem Management (GO-ITS 38) establishes the Enterprise Problem Management principles, roles and associated process model. These standard elements provide a single unified process for Enterprise Problem Management within the Ontario Public Service (OPS). Use of this single process and supporting information enables OPS-wide management and reporting through establishment of common data and associated metrics.
Part of a broader set of Information Technology Service Management (ITSM) process documentation that was initially created for use as a reference across the OPS, this document was first developed as a high-level portable guide to be used as a starting point for local implementations of Problem Management throughout the OPS.
Under the Ministry of Government Services Act, section 6, Infrastructure Technology Services (ITS) has the authority to acquire, manage and provide common services for the OPS by acting as a service provider or broker of infrastructure services. After the ITS organization was established in 2006 to deliver all IT infrastructure services to the OPS, a new requirement for an enterprise-level Problem Management standard emerged.
In February 2009, a series of outages to a major citizen-facing website prompted I&IT executive management to reprioritize the OPS Enterprise ITSM Program (OEIP) Roadmap so that a simplified enterprise Problem Management capability could be developed and made operational by the summer of 2009.
Updates to the existing GO-ITS included:
- Principles, roles, responsibilities and the high-level process flow required to support an enterprise Problem Management process
- Incorporation of ITIL V3 (2007) concepts including the introduction of a service-based focus on enterprise Problem Management and the evolution of IT service management disciplines within the OPS
In December 2011, the Service Management Branch of ITS was identified as the Enterprise Problem Management Process Owner by the IT Service Management Leads (ITSML) forum and given the task of updating the GO ITS 38 – Enterprise Problem Management Standard to establish a standard common Problem Management process for use by the OPS.
In May 2015, the OPS adopted a new Enterprise Service Management Tool that included updated terminology, features and roles that aligned with ITIL best practices. A complete review of the Problem Management Standard was undertaken at this time to update the different roles, responsibilities and terminology and to make the document Accessibility for Ontarians with Disabilities Act (AODA) compliant.
In 2018, ITELC requested additional updates to the document that would incorporate the use of Event Management and Incident Management to support proactive Problem Management.
The GO-ITS 44 ITSM Terminology Reference Model provides a common information model for key process parameters that require standardization across the OPS to ensure consistency, reliable business intelligence and to support end-to-end cross-jurisdictional service management. GO-ITS 44 will be updated with values defined as part of GO ITS 38.
Purpose
Problem Management is the process responsible for managing the lifecycle of all problems
The primary objectives of Problem Management are to:
- Prevent problems and resulting incidents/events from happening.
- Eliminate reoccurring incidents/events where root cause is not known.
- Minimize the impact of incidents that cannot be prevented.
- Develop and maintain meaningful, searchable records relating to problems.
- Develop, document and deploy known workarounds.
Value to business
Problem Management works together with Incident Management, Release Management, Event Management and Change Management to ensure the quality and availability of IT services. When incidents are resolved, information about the resolution is recorded. If incidents reoccur, this information is used to reduce the resolution time and identify permanent solutions, ultimately reducing the number of reoccurring incidents. This results in less downtime and less disruption to business systems.
The following benefits are realized from adopting Problem Management:
Risk reduction
- Problem Management reduces incidents resulting in more reliable, higher availability, and higher quality I&IT services to business users.
Cost reduction
- Reduction in the number of incidents leads to a more efficient use of staff time as well as decreased downtime experienced by end users.
- Problem Management reduces costs of implementing workarounds or temporary fixes that do not address the root cause.
Service quality improvement
- Problem Management helps I&IT organizations to meet customer expectations for I&IT services and, in turn, client satisfaction objectives.
- By understanding existing problems, Known Errors and their corresponding workarounds, Problem Management strengthens the OPS IT Service Desk through to Tier N’s ability to address incidents at first point of contact.
- Problem Management generates a cycle of increasing I&IT service quality.
Improved utilization of I&IT staff
- OPS IT Service Desk resources handle calls more efficiently because they have access to a knowledge database of Known Errors and possible workarounds.
- Consolidating Problems, Known Errors and corresponding workaround information facilitates organizational learning.
The business costs of not adopting a formal Problem Management process include the following:
- Business interruptions will result in unsatisfied clients and loss of confidence in the I&IT organization.
- Downtime results in a loss of productivity for the business.
- It is inefficient for senior support resources to spend their efforts reacting to incidents rather than pro-actively managing the delivery and support of services.
- Employees lose motivation when they are required to repeatedly address incidents with similar characteristics and it appears that I&IT Senior Management is not interested in addressing the root cause of service disruptions.
Basic concepts
Problem Management is focused on implementing the appropriate corrective actions to address problems that negatively impact IT services. It seeks to implement cost-effective, permanent solutions to eliminate the root cause of incidents thereby preventing reoccurrence. This differs from Incident Management which focuses on temporary workarounds to quickly restore service.
A problem is defined as the unknown cause of one or more incidents.
There are two main approaches to Problem Management: reactive and proactive.
- Reactive Problem Management identifies problems based on multiple Events or Incidents that exhibit common symptoms or in response to a single incident with significant impact. The Event or Incident should have had corrective action taken to remedy the situation. Problem Management is engaged when the issue reoccurs and the root cause is not known.
- Proactive Problem Management analyses incident records and other available IT data to identify trends or significant problems where the root cause is not known.
Additionally, Problem Management plays a role in a third approach known as Predictive Service Management:
- Predictive Service Management reviews available IT data over a period of time and analyzes it along with any correlations identified through Incident Records, Configuration Items and Changes Requests to predict future incidents. When future incidents are predicted, Problem Management may recommend workaround steps; this information is logged as a Known Error.
The basic steps associated with Problem Management include:
- detection of candidate problems via analysis of incident data, problem data, operational data, release data, knowledge databases and capacity or availability reports.
- logging, classification and prioritization of confirmed problems into the Problem Management database.
- determination of the root cause of the problems using industry standard techniques such as Kepner-Tregoe, Ishikawa Diagrams, Pain Value Analysis, Brainstorming and Technical Observation Post, and Pareto Analysis.
- logging and classification of Known Errors identified by either root cause analysis or information from other sources.
- determination of alternative corrective actions to resolve Known Errors.
- working with Change Management to implement appropriate corrective actions.
- deferring or closing the problem record as unresolved, at the discretion of the Problem Manager, in situations where the root cause cannot be determined within the scope of available resources.
The term Known Error is used in two ways:
- Known Error is a state in the problem lifecycle that represents successful diagnosis and identification of the root cause of a problem. Root causes can take many forms such as technology, procedures and documentation and user knowledge levels. They are targeted for resolution through short-term and/or long-term corrective actions. Examples of other sources of information used to identify Known Errors are:
- application variances maintained during build and test activities
- software release notes
- vendor release notes that accompany new products
- vendor patches
- online vendor support websites.
- Known Error is also used to describe the knowledge record containing details of the fault, symptoms, and any workarounds (also referred to as the Known Error database or KEDB). Sometimes the Known Error and problem information are consolidated into a single record. Known Error information should be used during incident diagnosis to facilitate a faster resolution.
The priority of a problem is determined primarily by the impact to the business and the resulting urgency for corrective actions. Urgency is determined by an assessment of the likelihood that a problem will cause future incidents.
Action may be deferred if not justified by the associated costs and/or impact to the business.
There are significant linkages between the Problem Management and Incident Management processes:
- Incident Management provides incident history information used by Problem Analysts to identify problems.
- Incident Management practitioners (and Service Desk Analysts) use problem and Known Error information when handling calls and resolving incidents.
- The recommended corrective action for a Known Error is initiated by the Problem Owner by raising a Change Request (CRQ) through the Enterprise Change Management (ECM) process.
- Problem records are linked with other records (incidents and CRQs) though process-enabling technology.
Inputs to the Problem Management process include
- incident records
- re-occurring incident data
- data from Major Incidents
- Event data
- potential problems (issues brought forward for consideration by customers, staff, senior management)
- workarounds from different sources/knowledge databases
- service availability requirements
- operational (event) data
- Release or Change data where a Known Error is being introduced into the environment
Outputs from the Problem Management process include
- consistent and meaningful application of infrastructure problem investigations and Known Error records
- CRQs (through ECM) for error removal
- problem escalation
- problem records (in knowledge database) linked to incidents, Known Errors and CRQs
- trend analysis results
- meaningful management information
- incident frequency reduction
- increased stability for application and infrastructure elements resulting in improved service.
Scope
The scope of Problem Management includes the activities required to diagnose the root cause of reoccurring incidents and to assist with the resolution to those problems. The Service Owner is responsible for ensuring that the resolution is implemented through the appropriate control procedures, primarily Change Management and Release Management.
Problem Management also maintains information about problems and the appropriate workarounds and resolutions to help the organization reduce the number and impact of incidents over time. In this respect, Problem Management has strong linkages with the Knowledge Management process and tools such as the Known Error Database
Although Incident and Problem Management are separate processes, they are closely related and typically use the same tools and may use similar categorization, impact and priority coding systems. This ensures communication when dealing with related incidents and problems
Compliance requirements
Execution of the Problem Management process at the operational level requires the use of procedures, work instructions and enabling technology to automate certain workflow aspects. The following statements are presented to ensure that these elements are fully compliant with this Standard:
Procedures must be developed by decomposing each process step into sub-tasks (see section ‘Enterprise Problem Management process tasks’). These procedures must be submitted to ITELC for certification that they comply with the spirit and intent of the process Standard.
Work instructions must be developed by decomposing all procedural sub-tasks into further sub-tasks. These must be then submitted to ITELC for certification that they comply with the certified process and procedures.
Functional requirements must be developed for enabling technology that will be used to automate aspects of the work instructions and procedures. Functional requirements must be submitted to ITELC for certification that they align with the certified procedures.
Any subsequent modifications to the procedures, work instructions or enabling technology must be managed via Enterprise Problem Management and will require authorization by ITELC.
Please refer to Appendix 5.3 for a diagrammatic explanation of process, procedure and work instructions.
Requirements levels
Within this document, certain wording conventions are followed. There are precise requirements and obligations associated with the following terms:
Must: This word, or the terms "required" or "shall", means that the statement is an absolute mandatory requirement.
Should: This word, or the adjective "recommended", means that there may exist valid reasons in particular circumstances to ignore the recommendation, but the full implications (e.g., business functionality, security, and cost) must be understood and carefully considered before deciding to ignore the recommendation.
3. Technical specification
Process principles
Principles are established to ensure that the process identifies the desired outcomes or behaviours related to adoption at an enterprise level. They also serve to provide direction for the development of procedures and (as necessary) work instructions that ensure consistent execution of the process. The absence of well-defined and well understood principles may result in process execution that is not aligned with the process Standard. Mandatory process principles for OPS Enterprise Problem Management are listed below.
Principle 1:
A single Problem Management process that is separate from the Incident Management process shall be used across the OPS.
Rationale:
- There is clear accountability for the Problem Management process.
- There is clear ownership for problem resolution.
- Resources can be focused on identifying the main and contributing root causes of a problem.
- There is a defined review process associated with addressing root causes and corrective actions.
- There is a consistent interface with groups responsible for resolving problems.
- Duplicate problem resolution activities are avoided.
Implications:
- Requires a base level of maturity for Incident Management.
- Sufficient designated resources must be focused on Problem Management.
- Process linkages with Incident Management must be clear.
- Incident and Problem Management are separately-managed processes.
Principle 2:
- Clear criteria shall be established to define what constitutes a problem and how problems will be prioritized.
Rationale:
- Protect the Problem Management process to ensure Problem Management resources are effectively focussed on real, not perceived problems.
- Ensure that a minimum level of information is captured to allow Problem Analysts to correctly assess and identify the problem for review.
- Ensure the most critical problems are addressed first.
- Ensure consistent treatment of reported incidents.
Implications:
- Only the Problem Manager will have the authority to approve and prioritize problems (by applying said criteria).
- At least one incident record or Known Error must exist before a problem record will be created via reactive Problem Management.
- Customer Relationship Management (CRM) and Service Level Management (SLM) functions do not have direct interface with the Problem Management process. They must provide Service Owners with sufficient evidence to warrant a candidate problem being identified to the Problem Manager by the Service Owner.
- Incident Management procedures must ensure that information required by Problem Management is captured during incident logging, classification and service restoration activities.
- The Incident Management process needs the ability to link similar incidents to an existing problem.
Principle 3:
All problem investigations, Known Errors and relevant progress and resolution information shall be recorded in a common repository that is linkable to other ITSM practices.
Rationale
- Provides source of reference for Problem Analysts (knowledge base).
- Captures historical knowledge of incidents and problems allowing for quicker diagnosis and resolution by Service Desk Analysts when incidents reoccur.
- Simplifies problem investigation and Known Error analysis and reporting.
- Provides a single source of data for integration with other ITSM processes and tools.
- Provides source data for process effectiveness and efficiency measurement.
Implications
- A common information model must be used to facilitate linkages among ITSM processes across the OPS.
- All Problem Investigations/Known Errors, progress and resolutions must be logged.
- Known Errors and related Problem Investigations must be linked.
- Historical and new reoccurring incidents must be linked to Problem Investigations and Known Errors.
- The number of reoccurring incidents must be captured since this information can influence problem investigation prioritization.
Principle 4:
- A Known Error shall be raised as soon as useful knowledge is available, even before a permanent resolution is found.
Rationale
- In some cases the root cause may never be determined. During the course of investigation and diagnosis, Known Errors may be identified before completion of root cause analysis. These Known Errors should be documented with workaround and other relevant information for use by Incident Management practitioners.
- In other cases such as vendor-issued patches/release notes or alarms from event monitoring systems, a Known Error could be identified without root cause analysis being undertaken.
- In the event that future incidents can be predicted, a Known Error will be created with any useful information.
Implications
- Service Owners must assess vendor information and if applicable to their service (including all components that enable the service) they must submit a Known Error to the Problem Manager. The underlying database needs to be structured to effectively handle different types of data: Known Errors, workarounds and general information.
- Parameters need to be defined to flag a problem record as Known Error and also to indicate whether the root cause is known.
Principle 5
- Known deficiencies in an implemented release or change shall be logged as a Known Error.
Rationale
- This ensures that known development and staging defects are documented.
- Details of workarounds and/or recommended actions (including “no action required”) can be used by Incident Management practitioners to clarify expectations and avoid unnecessary investigation and diagnosis activities.
- Knowledge of defects should be factored into risk-impact assessments when planning future changes.
Implications
- In the absence of a formal release and deployment management process, the Change Owner must submit a Known Error to Problem Management (which references the CRQ #).
- The linkage between Change Management and Problem Management must be defined and adhered to.
- Resolution of such deficiencies will not be addressed by Problem Management, but by the Service Owner who has consciously accepted and introduced this deficiency. Meanwhile, the Known Error is available for Incident Management practitioners to resolve incidents against and associate to the Known Error.
Principle 6:
Problem investigations and diagnoses shall employ standard analysis techniques and methodologies leveraging industry best practices.
Rationale
- To ensure that effective Problem Management analysis tools and techniques are adopted and consistently applied throughout the enterprise.
Implications
- Resources involved in the Problem Management process require specific training related to root cause analysis techniques.
- This requires identification, documentation and training on standard tools and analysis techniques beyond the guidance in the process and procedure guide.
- There is a defined review process associated with addressing root causes and corrective actions.
Principle 7:
Service Owners must fulfill their roles and responsibilities as defined in this Problem Management process.
Rationale:
- Service Owners are usually assigned as Problem Owners, accountable to manage problem resolution for owned services.
- Service Owners are accountable for IT Assets and Components that are impacted by corrective actions.
- Service Owners have to secure funding for resolution activities.
Implications:
- Service Owners have to reprioritize existing workload to manage assigned problems within service objectives.
- Service Owners must ensure that their Service Level Agreements and Underpinning Contracts contain explicit language that will require internal and external Service Providers to support OPS Problem Management activities, including analysis and implementation of solutions to eliminate problems.
- Service Owners have to secure funding from the Service Manager to enable problem resolution (e.g. additional hardware, new/upgraded software, new solution development).
- Service Owners must be identified for all designated services.
4. Process roles and responsibilities
Each process requires specific roles to undertake defined responsibilities for process design, development, execution and management. An organization may choose to assign more than one role to an individual. Similarly, the responsibilities of one role could be mapped to multiple individuals.
One role is accountable for each process activity. With appropriate consideration of the required skills and managerial capability, this person may delegate certain responsibilities to other individuals. However, it is ultimately the job of the person who is accountable to ensure that the job gets done.
Regardless of the mapping of responsibilities within an organization, specific roles are necessary for the proper operation and management of the process. This section lists the mandatory roles and responsibilities that must be established to execute the Problem Management process.
Legend:
R: Responsible
A: Accountable
C: Consulted
I: Informed
| Process activities | Problem manager | Problem coordinator | Problem analyst | Problem liaison | Service owner |
|---|---|---|---|---|---|
| 1.0 Problem Detection | R | R | R | R | AR |
| 2.0 Problem Logging, Classification, and Prioritization | A | R | R | I | C |
| 3.0 Investigation & Diagnosis | N/A | C | R | C | AR |
| 4.0 Known Error Record | A | R | C | I | I |
| 5.0 Completion | C | C | R | I | AR |
| 6.0 Closure | A | R | C | I | C |
| 7.0 Critical Problem Review | AR | C | C | C | R |
Enterprise Problem Management Process Owner
The Enterprise Problem Management Process Owner owns the process and the supporting documentation for the process being described. This includes accountability for setting policy and providing leadership and direction for the development, design and integration of the process as it applies to other applicable frameworks and related ITSM processes being used and or adopted in the OPS. The Enterprise Process Owner is accountable for the overall health and success of the process.
Responsibilities
- Is responsible for and owns the overall Enterprise Problem Management process.
- Ensures that the process is defined, documented, maintained and communicated at an enterprise level through appropriate means.
- Undertakes periodic reviews of all ITSM processes from an enterprise perspective and ensures that a methodology of continuous service improvement, including applicable process-level supporting metrics, is in place to address shortcomings and evolving requirements.
- Takes into consideration OPS policies and directives and factors in evolving trends in technology and practice, ensuring that all enterprise ITSM processes are considered and managed in an integrated manner.
- Solicits OPS stakeholders and communities of interest to establish enterprise ITSM process requirements for consideration by the enterprise ITSM program; coordinates, presents and recommends options for the prioritization, development and delivery of these to the appropriate governing body.
- Ensures enterprise process requirements are documented and provided to operational support teams to be developed and implemented with enabling technology.
Segregation of duties
The role of the Enterprise Problem Management Process Owner is separate and distinct from that of the Enterprise Problem Manager and the roles shall be separately staffed. The Enterprise Problem Management Process Owner shall be the Head of the ITS Process and Operations Branch while the Enterprise Problem Manager shall reside within the ITS Process and Operations Branch Process Management Office.
Enterprise Problem Manager
The Enterprise Problem Manager is responsible for managing the lifecycle of all problems with a primary objective to prevent reoccurring incidents from happening, and to minimize the impact of incidents that cannot be prevented. The Enterprise Problem Manager has the ultimate accountability for resolution of problems and is the escalation point for Problem Management activities.
Responsibilities
- Develops and maintains operational procedures to execute the Enterprise Problem Management process.
- Develops and maintains functional requirements for enabling technology and corresponding usage guidelines.
- Ensures close linkages between Enterprise Problem Management and all Service Management practice areas at the operational level (including linkages to enabling technology).
- Monitors and reports on various attributes of the Problem Management process and identifies improvement opportunities to the Enterprise Process Owner:
- process efficiency
- process/procedural adherence
- process effectiveness (i.e. reduction in number of incidents)
- service level performance of the Problem Management process
- Uses matrix management and assistance from Problem Management Liaisons to:
- ensure that Problem Analysts (from all organizations) are assigned at an appropriate level, with adequate skill levels and training in standard Problem Management techniques
- assess the effectiveness of Problem Management activities and identify need for further training of Problem Analysts
- Manages and coordinates all activities necessary to detect problems by ensuring analysis of Incident Management data and other relevant sources of information.
- Authorizes the creation of problem records and prioritizes problem activities.
- Assigns problems to the appropriate Service Owner for analysis and resolution.
- Assigns Problem Analyst(s) to support Service Owners in their activities.
- Ensures creation and maintenance of the Known Error Database, including approval of Known Errors.
- Monitors assigned problems and takes appropriate action if activities are not conducted within process performance objectives (PPO).
- Ensures that a Critical Problem Review is completed when necessary.
Service Owner
The Service Owner has ultimate responsibility for analysis and resolution of assigned problems. The Service Owner is accountable for a specific service within an organization regardless of where the underpinning technology components, processes or professional capabilities reside.
Responsibilities
- Resolves known deficiencies introduced through Change Management and Release Management activities as well as ensures Known Error records are raised for such deficiencies.
- Reprioritizes existing workload to manage assigned problems within service objectives.
- Ensures that Service Level Agreements and urgent changes contain explicit language that will require internal and external Service Providers to support OPS Problem Management activities, including analysis and implementation of solutions to eliminate problems.
- Secures funding to enable problem resolution (e.g. additional hardware, new/upgraded software, new solution development).
- Provides executive support for the process within their service area.
- Acts as point of escalation (notification) for Problem Management.
- Ensures required stakeholders are involved in the Problem Management activities.
- Utilizes a matrix management approach to plan, manage and coordinate activities necessary to identify root cause, develop workarounds, preventative actions and long-term solutions for assigned problems.
- Ensures through Problem Management Liaison, that support staff in their service area have adequate skill levels and training in Problem Management techniques.
- Creates Change Requests to assist with Problem Management activities.
- Ensures affiliated Vendor(s) adheres to the Principles of Problem Management.
Problem Coordinator
The Problem Coordinator is the Problem Management process subject matter expert (SME). They execute the Problem Management process and coordinate the activities required to respond to problems in compliance with Service Level Agreements (SLAs) and Service Level Offering (SLOs). The Problem Coordinator supports the Enterprise Problem Manager, Problem Analyst, and Problem Management Liaisons, with reporting, follow up, and gathering details for authorization and escalation tasks.
Responsibilities
- Coordinates activities necessary to detect problems and identify root cause and workarounds.
- Assists the Problem Manager in data analysis to identify suspected problems.
- Analyzes Incident Management data (records and the consolidation list).
- Ensures maintenance of the Known Error Database and liaises with the Service Desk to identify potential Knowledge Records.
- Works with Problem Analysts to expedite and follow up on stale problems.
- Monitors and reports on Problem Management process activities and identifies improvement opportunities.
- Provides guidance to Problem Analysts on Problem Management best practices and analysis tools and techniques.
- Provides input to the continuous service improvement (CSI) initiatives driven by the Problem Management process.
- Engages required support staff from other organizations via Problem Management Liaisons and/or Problem Analysts.
- Assigns appropriate tasks to engage other support groups or vendors.
Problem Analyst
The Problem Analyst provides skills and knowledge in a particular domain (technical, operational or application). They are also trained in best practice techniques for problem investigation. They use this expertise to facilitate root cause analysis of assigned problems, and the development of workarounds and/or permanent solutions with the assistance of appropriate SMEs.
Responsibilities
- Leads investigation activities and is the main point of collaboration with Service Chain Partners.
- Uses standard problem analysis techniques to facilitate identification and validation of root cause.
- In collaboration with SMEs and Service Owners:
- facilitates development of workarounds and short-term corrective actions for Known Errors
- facilitates development and testing of permanent solution
- Records and updates problem and Known Error records with appropriate information.
- Assists in validating that root cause has been eliminated upon implementation of the recommended solution.
- Collaborates with other Problem Analysts in their jurisdiction or between jurisdictions for a multi-jurisdiction problem.
- Highlights areas of escalation to the Problem Coordinator and/or Problem Manager.
- Provides input to the CSI initiatives driven by the Problem Management process.
- Engages required support staff from other organizations via Problem Management Liaisons and/or Problem Coordinators.
Problem Management Liaison
The Problem Management Liaison provides a point of contact between the Problem Manager and partner organizations (e.g. Clusters, ITS, CSB, third-party service providers) to enable effective and efficient execution of the Enterprise Problem Management process.
Responsibilities
- Identifies required participants (Problem Analysts and SMEs) from other organizations to the Problem Manager.
- Assists in prioritizing organizational problems; manages and coordinates all partner activities necessary to detect problems and identify/record root cause and workarounds of logged problems.
- Identifies and confirms the assignment of resources with the accountable manager within their organization to work on Problem Management activities, including escalation if unable to secure resources.
- Ensures partner support staff have adequate training and skill levels to execute the Problem Management process and monitors their performance of Problem Management activities.
- Ensures required Service Owners are involved in the process and engages the Problem Manager and upper levels of local management as appropriate.
- Monitors and reports on partner Problem Management process activities and identifies improvement opportunities to the Problem Manager.
Process flow
Enterprise problem management process overview
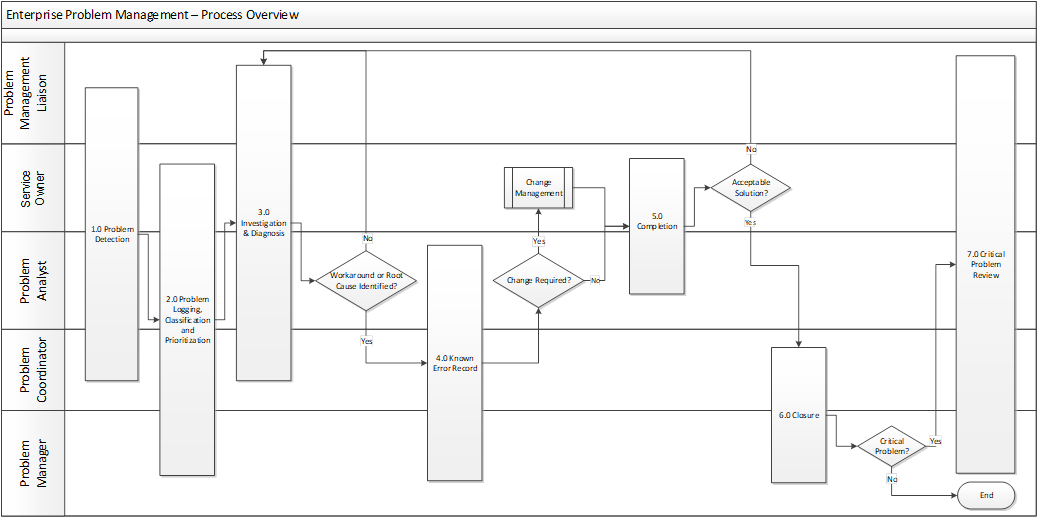
Accessible Description of the Problem Management Process Overview
Enterprise problem management process tasks
The following table lists the mandatory tasks to be performed during execution of the Problem Management process.
Roles legend
PM - Enterprise Problem Manager
PC - Problem Coordinator
PA - Problem Analyst
SO - Service Owner
PML - Problem Management Liaison
| No. | Task | Roles | Input, trigger | Description | Output, completion criteria |
|---|---|---|---|---|---|
| 1.0 | Problem Detection | PML SO PC PA |
Input: Incident database, incident trend reports, service metrics reports, event data, patterns Trigger: Release notifications, multiple incidents, major incidents | Identify possible problem areas by analyzing incident data, problem data, operational data, release notes, knowledge database and capacity or availability reports. | Problem identified |
| 2.0 | Problem Logging, Classification and Prioritization | SO PA PC PM |
Problem identified | Log a problem record, including all relevant information and links to associated Incident, Change and Configuration Item records.
Classify the problem; determine the impact and urgency to set the priority of resolution The SO and PA are identified and assigned to the problem. |
Logged, classified, prioritized, and assigned problem record |
| 3.0 | Investigation & Diagnosis | PML SO PA |
Logged problem record | The PA uses standard problem analysis techniques to diagnose and validate root cause of the problem.
Once root cause or a workaround is found, a Known Error record is created and the solution is implemented as required. If the solution (root cause or workaround) is accepted by the SO, the problem can be resolved; else, the investigation and diagnosis continues. If a decision is not to proceed, or if a permanent solution cannot be found, the problem is closed as unresolved. If support is required from other organizations, PML can assist with obtaining SME support, as required, within their organizations. |
Identified root cause, workaround, or unresolved problem. |
| 4.0 | Known Error Record | PA PC PM |
Identified root cause, workaround, or unresolved problem. | As soon as a workaround or root cause has been identified, even if it is not a permanent solution, a Known Error record must be raised. If further incidents or problems are raised they can be identified and the service restored more quickly.
A Known Error record should be logged for an accepted unresolved problem to ensure cycles are not wasted in diagnosing and attempting to resolve a known and accepted deficiency. |
Known Error record |
| 5.0 | Completion | SO PA |
Identified root cause, workaround | Implementation of the solution via the appropriate change process.
If the solution is a workaround, the SO can decide if this is an acceptable permanent solution. If not, the process falls back to the investigation and diagnosis phase. If a permanent solution has been identified, the SO will determine whether sufficient cost justification exists to proceed with a permanent solution. If not, the problem will be closed as Deferred and related records updated as necessary. |
Implemented solution to remove root cause or workaround OR No further action |
| 6.0 | Closure | PC PM |
Removed root cause, workaround, deferred problem | The problem record is updated to reflect all activities carried out during problem investigation and resolution.
The status of any related Known Error records should be updated to show that the resolution has been applied. |
Problem Investigation Closed |
| 7.0 | Critical Problem Review | PML SO PA PC PM |
Completed problem investigation | After every critical problem, a review should be conducted by the Problem Manager to identify any lessons learned or potential CSI initiatives. | Completed Critical Problem Review |
Linkages to other processes
| Process | Linkage |
|---|---|
| Enterprise incident management (eIM) |
|
| Enterprise change management (eCM) |
|
| Enterprise service asset and configuration management (eSACM) | Problem Management uses the Configuration Management Database (CMDB) to identify faulty CIs and to determine the impact of problems and resolutions. |
| Enterprise release management (eRM) | Problem Management assists in ensuring that any associated Known Errors are transferred from the development Known Error Database into the production Known Error Database. |
| Enterprise service level management (eSLM) |
|
| Event management | Event Management provides Problem Management with information on events and possible future incidents occurring within the IT infrastructure that may have an impact to IT services and CIs. |
Problem management process quality control (CSI)
There are activities related to the management of the Problem Management process that are intended to control quality as well as to ensure that the process is both effective and efficient. These activities happen in parallel to the execution of the process.
Monitoring of the service delivered by the Problem Management team is performed regularly by the Problem Manager. This allows the Problem Manager to answer any questions about service quality and customer satisfaction as well as ensure that the Problem Management process is not running into resource or ownership issues. The Problem Manager is responsible for taking corrective actions if bottlenecks are identified in the process.
Reporting involves measuring the process through metrics and recording how well it behaves in relation to the objectives or targets specified in the metrics. Metrics provide the Problem Management team with feedback on the process. They also provide the Problem Management Process Owner with the necessary information to review overall process health and to undertake continuous service improvement initiatives.
Evaluating the process involves regular reviews of the performance of the process and identification of possible improvements or actions to address performance gaps. Every process is only as good as its last improvement; hence, the feedback loop of continuous improvement is inherent in every process.
Metrics
Metrics are intended to provide a useful measurement of a process effectiveness and efficiency. Metrics are also required for strategic decision support. The following need careful consideration:
- Reporting metrics will be readily measurable (preferably automated collection and presentation of data)
- Metrics will be chosen to reflect process activity (how much work is done?), process quality (how well was it done?) and process operation (to review and plan job on hand).
- The Enterprise Problem Management Process Owner is accountable for the definition and capture of an appropriate suite of metrics to determine the overall health of the Enterprise Problem Management process.
The following metrics must be used to assess process performance, opportunities for service improvements and for strategic decision support.
Workload
- The total number of problems recorded in the period.
- Number of problems and Known Errors in a period broken down by status, service, impact, category and closure condition code.
Process effectiveness
Determination of Problem Management effectiveness requires metrics input and analysis across a number of processes: Incident Management, Service Level Management and Problem Management. The following represent a suite of Problem Management-related metrics that must be provided by these processes:
- number of reoccurring incidents (per service) (IM)
- number of incidents (IM)
- number of incidents resolved via workarounds from Known Errors (IM)
- number of problems that reoccur (PM)
- percentage of SLA targets achieved (SLM)
- percentage service component availability (SLM)
- number of open Known Errors and status of associated change requests
- number of deferred corrective actions (PM)
- number of Incidents linked to problem records (PM)
Process efficiency
Metrics are used to analyze the performance of the process in order to determine areas for improvement (e.g. increase in average time to resolve problems may indicate need for more training or tools):
- average effort of handling a problem
- number and percentage of problems that exceeded their target resolution times
- backlog of outstanding problems and the trend (static, reducing or increasing?)
- volume and percentage of problems processed per period with no resolution
- average time to find root cause
- average time to identify permanent solution
Standard process parameters
For an enterprise process to be effective, parameters used for the classification, categorization, prioritization and closure of problems must be used consistently used across the OPS. Special attention must be given to parameters related to consistency of reporting. This is particularly important for the provision of reliable business intelligence.
Please refer to the Classification Model section of the GO-ITS 44 ITSM Terminology Reference Model for standard process parameters and allowable values for Problem Management.
Please refer to the State Model section of the GO-ITS 44 ITSM Terminology Reference Model for standard status/state parameters and their definitions for Problem Management.
5. Standards lifecycle management
Contact information
Accountable role (standard owner) definition
The individual or committee ultimately accountable for the process of developing and maintaining this standard. Where a committee owns the standard, the committee chair is accountable for developing the standard including future updates. There must be exactly one accountable role identified.
Accountable role:
Title: Chair, Service Management Executive Committee (SMX)
Responsible role definition
The organization(s) responsible for the development of this standard. There may be more than one responsible organization identified if it is a partnership/joint effort. (Note: the responsible organization(s) provides the resource(s) to develop the standard).
Responsible organization(s):
Ministry: Ministry of Public and Business Service Delivery (MPBSD)
Division: Infrastructure Technology Services (ITS)
Branch: Service Management Process & Operations
Support role definition
The support role is the resource(s) to whom the responsibility for developing and maintaining this standard has been assigned.
Support role (editor):
Ministry: Ministry of Public and Business Service Delivery (MPBSD)
Division: Infrastructure Technology Services (ITS)
Branch: Service Management Process & Operations
Section: ITSM Processes
Job Title: Senior Manager
Name: Arpad Martonosi
Phone:
Email: Arpad.Martonosi@ontario.ca
Job Title: Delegate 1:
Name: Praveen Ravindranathan
Phone:
Email: Praveen.Ravindranathan@ontario.ca
Job Title: Delegate 2:
Name: Mike Williams
Phone:
Email: mike.williams2@ontario.ca
6. Related standards
Impacts to existing standards
Identify any standards that reference or are referenced by this standard and describe the impact.
| GO-IT Standard | Impact | Recommended action |
|---|---|---|
| GO-ITS 37 – Enterprise Incident Management | No impact | N/A |
| GO-ITS 35 - Enterprise Change Management | This standard is being updated in parallel and will reflect process linkages described above. | N/A |
| GO-ITS 44 ITSM Terminology Reference Model | Definition for Predictive Service Management needs to align | N/A |
| GO-ITS 36 – Enterprise Service Asset Configuration Management | No impact | N/A |
Impacts to existing environment
| Impacted infrastructure | Impact | Recommended action |
|---|---|---|
| Not applicable | N/A | N/A |
7. Consultations
| Committee/Working Group consulted | Date |
|---|---|
| Problem Management Community of Practice | December 16, 2016 February 24, 2017 May 26, 2017 August 29, 2019 Feb 24, 2022 |
| Process & Standards Sub-Committee (PSSC) | June 22, 2017 Feb 24, 2022 |
| Information Technology Service Management (ITSM) Leads | May 7, 2009 May 13, 2009 February 2013 July 13, 2017 |
| Architecture Review Board (ARB) | September 13, 2017 |
8. Appendices
Normative references
Enterprise Problem Manager will determine if procedures are a normative or informative reference and how they will be managed/evolved.
Informative references
Not applicable.
Differentiation: Process, Procedure, Work Instruction
Note: The following diagram depicts an example of three levels of task descriptions that are often confused with one another:
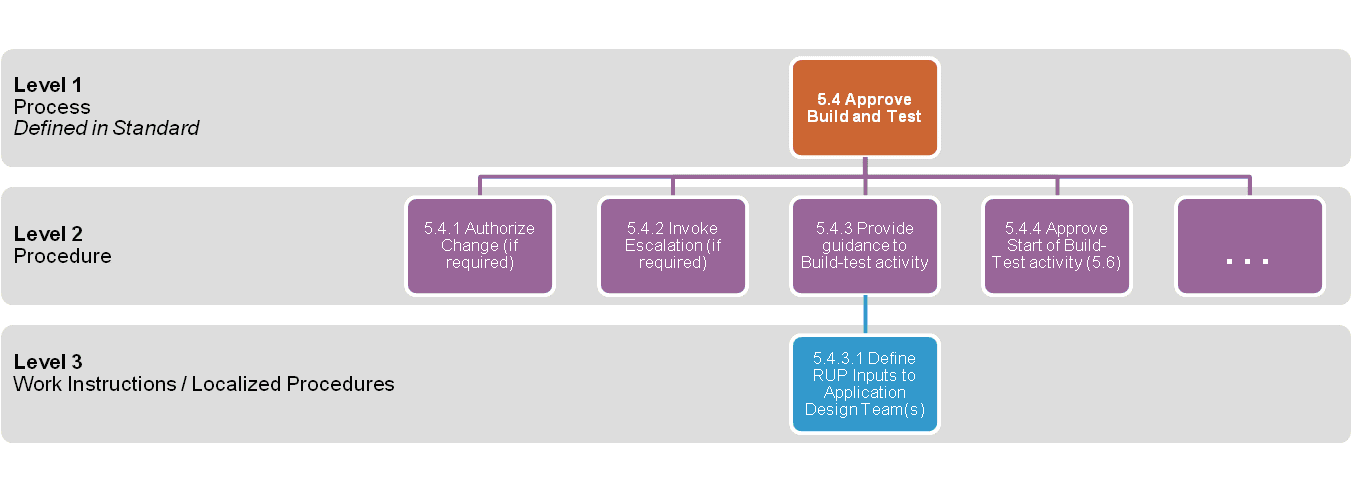
Accessible Description of Differentiation
Level 1 tasks are defined in a process. They specify what action must be taken and who is involved.
Level 2 tasks are defined in procedures which decompose each level 1 task into more granular operational tasks, and additionally, prescribe how the activity should be performed.
Level 3 tasks represent work instructions. They are further decomposition of procedure-level tasks which typically are defined to address any unique local requirements when performing a procedural task.
Definitions: Impact, Urgency, and Priority
The following table provides the framework for classifying the impact and urgency of problems, which are then used to establish problem priority. Impact and urgency were originally defined in the GO-ITS 44 Terminology Reference Model (TRM), to ensure that local process implementations used common terminology. ITSM has matured across the OPS and enterprise processes are now in place for Incident, Problem, Change and Service Asset and Configuration Management. The definitions have been updated to reflect best practices. This is the first step in relocation of classification elements from the TRM into the corresponding ITSM process standard.
| Classifications | Definitions | Field values | Criteria (At least 1 criteria must be met) |
|---|---|---|---|
| Impact | Measure of scope and criticality to business. Often equal to the extent to which a problem leads, or may lead to, distortion of agreed or expected service levels. Impact is often measured by the number of people, critical systems affected, or by the financial loss resulting from the service interruption. Problems may default to a pre-defined impact based upon the service category, component category and incident/problem type. |
1‐Extensive/ Widespread | Application, service, or infrastructure problem resulting in major incidents that effect:
|
| Impact | Measure of scope and criticality to business. Often equal to the extent to which a problem leads, or may lead to, distortion of agreed or expected service levels. Impact is often measured by the number of people, critical systems affected, or by the financial loss resulting from the service interruption. Problems may default to a pre-defined impact based upon the service category, component category and incident/problem type. |
2‐Significant/ Large | Application, service, or infrastructure problem resulting in incidents that effect a localized group (e.g. region, district) or a significant degradation in IT service affecting localized group(s):
|
| Impact | Measure of scope and criticality to business. Often equal to the extent to which a problem leads, or may lead to, distortion of agreed or expected service levels. Impact is often measured by the number of people, critical systems affected, or by the financial loss resulting from the service interruption. Problems may default to a pre-defined impact based upon the service category, component category and incident/problem type. |
3‐Moderate/ Limited | Application, service, or infrastructure problem resulting in incidents that effect:
|
| Impact | Measure of scope and criticality to business. Often equal to the extent to which a problem leads, or may lead to, distortion of agreed or expected service levels. Impact is often measured by the number of people, critical systems affected, or by the financial loss resulting from the service interruption. Problems may default to a pre-defined impact based upon the service category, component category and incident/problem type. |
4‐Minor/ Localized | Application, service, or infrastructure problem resulting in incidents or alerts that are non-service impacting. |
| Urgency | Measures how quickly a problem needs to be responded to base on the business needs of the customer and how long it will be until the problem has a significant impact on the business. Urgency is decided by assessment of the likelihood that problem will cause future incidents. |
1‐Critical | The problem will almost certainly reoccur within a week. A workaround has not been identified and a degraded mode of operation is not available or not acceptable. |
| Urgency | Measures how quickly a problem needs to be responded to base on the business needs of the customer and how long it will be until the problem has a significant impact on the business. Urgency is decided by assessment of the likelihood that problem will cause future incidents. |
2‐High | The problem will reoccur but not likely in the next week. A workaround has been identified or a degraded mode of operation is available and acceptable. |
| Urgency | Measures how quickly a problem needs to be responded to base on the business needs of the customer and how long it will be until the problem has a significant impact on the business. Urgency is decided by assessment of the likelihood that problem will cause future incidents. |
3‐Medium | The problem is not likely to reoccur. A workaround has been identified or a degraded mode of operation is available and acceptable. |
| Urgency | Measures how quickly a problem needs to be responded to base on the business needs of the customer and how long it will be until the problem has a significant impact on the business. Urgency is decided by assessment of the likelihood that problem will cause future incidents. |
4‐Low | The problem is non-service impacting and not likely to ever impact service. |
Priority
The priority of a problem is primarily determined by the impact to the business and the resulting urgency for corrective actions. Urgency is decided by an assessment of the likelihood that the problem will cause future incidents. Problem prioritization uses an impact/urgency matrix similar to Incident Management.
| Priority | Description |
|---|---|
| Critical | High likelihood of reoccurrence and high visibility/impact of incidents
No workaround is available, and a degraded mode of operation is not available or not acceptable Problem record must be updated every three business days. |
| High | Likely to reoccur, impact of resulting incidents will cause significant impact to the client
A workaround is available or a degraded mode of operation is available and acceptable Ticket must be updated every seven business days. |
| Medium | Low likelihood of reoccurrence, low impact of resulting incidents
Ticket must be updated every 15 business days. |
| Low | No impact to service. Problem must be updated every 30 business days. |
| Priority Matrix | Impact 1 - Extensive/ Widespread | Impact 2 - Significant/Large | Impact 3 - Moderate/Limited | Impact 4 - Minor/Localized |
|---|---|---|---|---|
| Urgency 1 - Critical | Critical | High | Medium | Medium |
| Urgency 2 - High | High | High | Medium | Medium |
| Urgency 3 - Medium | Medium | Medium | Medium | Medium |
| Urgency 4 - Low | Medium | Medium | Medium | Low |
9. Glossary
- CRQ
- Change request.
- Complexity
- The degree of Problem Analyst involvement required to isolate the root cause.
- Configuration Item (CI)
- A Configuration Item (CI) represents any component that needs to be managed in order to deliver an IT Service and is stored within the CMDB. A CI is maintained throughout its Lifecycle by eSACM. CIs typically include IT Services, Cloud Hosting instances, hardware, software, buildings, people, and formal documentation such as process documentation and SLAs.
- Enterprise Change Management (ECM)
- The Enterprise Change Management Process GO-ITS 35 Standard.
- Enterprise Service Asset Configuration Management (eSACM)
- The process responsible for ensuring that the assets required to deliver IT services are properly controlled and that accurate and reliable information about those assets is available when and where it is needed. This information includes details of how the assets have been configured and the relationships between assets.
- Error
- (Service Operation) A design flaw or malfunction that causes a failure of one or more configuration items or IT services. A mistake made by a person or a faulty process that affects a CI or IT service is also an Error.
- Escalation
- An activity that obtains additional resources when these are needed to meet service level targets or customer expectations. Escalation may be needed within any service management process, but is most commonly associated with Incident Management, Problem Management and the management of customer complaints. There are two types of escalations: functional escalation and hierarchical escalation.
- External service provider
- An IT service provider that is not part of the OPS. An IT service provider may have both internal customers and external customers.
- Functional escalation
- Transferring an incident, problem or change to a technical team with a higher level of expertise to assist in an escalation.
- Hierarchical escalation
- Informing or involving more senior levels of management to assist in an escalation.
- Impact
- A measure of the effect of an incident, problem or change on business processes. Impact is often based on how service levels will be affected. Impact and urgency are used to assign priority.
- Incident
- An unplanned interruption to an IT service or reduction in the quality of an IT service. Failure of a configuration item that has not yet affected a service is also an incident; for example, failure of one disk from a mirror set.
- Incident Management
- The process responsible for managing the lifecycle of all incidents. The primary objective of Incident Management is to return the IT service to customers as quickly as possible.
- Incident record
- A record containing the details of an incident. Each incident record documents the lifecycle of a single incident.
- Internal service provider
- An IT service provider that is part of the OPS. An IT service provider may have both internal customers and external customers.
- Ishikawa Diagram
- A technique that helps a team to identify all the possible causes of a problem. Originally devised by Kaoru Ishikawa, the output of this technique is a diagram that looks like a fishbone.
- IT service
- A service provided to one or more customers by an IT service provider. An IT service is based on the use of information technology and supports the customer’s business processes. An IT service is made up from a combination of people, processes and technology and should be defined in a Service Level Agreement.
- Kepner & Tregoe Analysis
- A structured approach to problem solving. The problem is analysed in terms of what, where, when and extent. Possible causes are identified. The most probable cause is tested. The true cause is verified.
- Known Error (KE)
- A KE has two distinct meanings:
- the lifecycle state of a problem that has successfully identified the root cause
- the records that document root cause details and available workarounds.
- Known Error database
- A database containing all Known Error records. This database is maintained by Problem Management and used by Incident and Problem Management.
- Known Error record
- A record containing the details of a Known Error. Each Known Error record documents the lifecycle of a Known Error, including the status, root cause and workaround. In some implementations a Known Error is documented using additional fields in a problem record.
- Operational Level Agreement (OLA)
- An agreement between an IT Service Owner and another IT Service Owner within the same organization. One Service Owner provides services that support delivery of IT services to the other Service Owner’s customers. The OLA defines targets and responsibilities that are required to meet agreed service level targets in an SLA. The OLA defines the goods or services to be provided and the responsibilities of both parties. For example there could be an OLA:
- between the IT service provider and a procurement department to obtain hardware in agreed times
- between the Service Desk and a support group to provide incident resolution in agreed times.
- Enterprise Process Manager
- A role responsible for operational management of a process. The Process Manager’s responsibilities include planning and coordination of all activities required to carry out, monitor and report on the process. There may be several Process Managers for one process; for example, regional Change Managers or IT Service Continuity Managers for each data centre.
- Enterprise Process Owner
- A role responsible for ensuring that a process is fit for purpose. The Process Owner’s responsibilities include sponsorship, design, change management and continuous improvement of the process and its metrics.
- Process Service Level Objective (PSLO)
- A service level objective for a specific process task or metric. e.g.:
- problem resolution will complete within x weeks, based upon problem classification.
- 70 percent of incidents will be linked to problems.
- Proactive Problem Management
- An approach included in the Problem Management process. The objective of proactive problem management is to identify problems that might otherwise be missed. Proactive problem management analyses incident records, and uses data collected by other IT Service Management processes to identify trends or significant problems.
- Problem
- A cause of one or more incidents. The cause is not usually known at the time a problem record is created, and the Problem Management process is responsible for further investigation.
- Problem Management
- The process responsible for managing the lifecycle of all problems. The primary objectives of Problem Management are to prevent incidents from happening, and to minimize the impact of incidents that cannot be prevented.
- Problem record
- A record containing the details of a problem. Each problem record documents the lifecycle of a single problem.
- Reactive problem management
- Reactive problem management involves the identification of problems based upon investigation of incident data, operational event data, and information provided by Service Desk and Service Owners.
- Release
- A collection of hardware, software, documentation, processes or other components required to implement one or more approved changes to IT services. The contents of each release are managed, tested, and deployed as a single entity.
- Root cause
- The underlying or original cause of an incident or problem.
- Root Cause Analysis (RCA)
- An activity that identifies the root cause of an incident or problem.
- Service
- ITIL defines service as “a means of delivering value to customers by facilitating specific outcomes customers want to achieve without the ownership of specific costs and risks”. GO-ITS 56.1 defines services within the OPS as functionality that can be directly consumed by an end user. Relationships and obligations between Service Owners and customers are documented in SLAs. (see Support Service)
- Service Desk
- The single point of contact between the service provider and the users. A typical Service Desk manages incidents and service requests, and also handles communication with the users.
- Service Failure Analysis (SFA)
- An activity that identifies underlying causes of one or more IT service interruptions. SFA identifies opportunities to improve the IT service provider’s processes and tools, and not just the IT Infrastructure. SFA is a time-constrained, project-like activity, rather than an ongoing process of analysis. See also Root Cause Analysis.
- Service Level Agreement (SLA)
- An agreement between an IT service provider and a customer.
The SLA describes the IT service, documents service level targets, and specifies the responsibilities of the IT service provider and the customer.
A single SLA may cover multiple IT services or multiple customers.
(See also Operational Level Agreement and Underpinning Contract)
- Service Level Manager
- Is the liaison between the business (customer) and IT who ensures that the agreed level of service is provided for current IT services, corrective action is taken if not, and that future IT services are delivered to agreed achievable targets.
- Service Owner
- Member of a service provider organization, accountable for delivery of a specific service.
- Service Manager
- A manager who is responsible for managing the end-to-end lifecycle of one or more IT services.
- Service Provider
- An organization supplying services to one or more internal customers or external customers.
Service provider is often used as an abbreviation for IT service provider.
Where there are several service providers that enable an overarching service, they are sometimes called supply chain (or service chain) partners.
- Support service
- Internal services that support a ‘consumable’ service. Support services are typically not visible to end users. Relationships and obligations between service support owners and their customer (Service Owners) are documented in OLAs and UCs. (see Service)
- Trend analysis
- Analysis of data to identify time-related patterns. Trend analysis is used in Problem Management to identify common failures or fragile configuration items, and in Capacity Management as a modelling tool to predict future behaviour. It is also used as a management tool for identifying deficiencies in IT Service Management processes.
- Underpinning Contract (UC)
- Contract between an OPS IT service provider and an external third- party IT service provider.
The third-party provides goods or services that support delivery of an IT service to a customer.
The UC defines targets and responsibilities that are required to meet agreed service level targets in an SLA and also specifies the required behaviour to comply with OPS ITSM standards.
- Urgency
- A measure of how long it will be until an incident, problem or change has a significant impact on the business. For example, a high-impact incident may have low urgency, if the impact will not affect the business until the end of the financial year. Impact and urgency are used to assign priority.
- Workaround
- Reducing or eliminating the impact of an incident or problem for which a full resolution is not yet available; for example, by restarting a failed configuration item. Workarounds for problems are documented in Known Error records. Workarounds for incidents that do not have associated problem records are documented in the incident record.
Document history
| Date | Summary |
|---|---|
| 2022-11-24 | IT Executive Leadership Council approval – Approved version number set to 3.1 |
| 2022-10-05 | Architecture Review Board endorsement |
| 2021-08-31 | Update for Accessibility compliance, Annual review / true up |
| 2020-07-16 | IT Executive Leadership Council approval – Approved version number set to 3.0 |
| 2020-05-20 | Architecture Review Board endorsement |
| 2019-08 | Full document review, history of document edited, Known Error principle added |
| 2017 | IT Executive Leadership Council (pending) |
| 2017-09-13 | Architecture Review Board endorsement of draft version 3.1 |
| 2017-07-05 | Updated to reflect recent Consulted Committees and Working Groups |
| 2016-10-24 | Updated to reflect eSM Organization |
| 2016-07-19 | Updated to reflect response of ITS feedback and process maturity |
| 2013-01-02 | Updated to reflect ownership change of eProblem to ITS and alignment with ITIL v3 |
| 2009-08-27 | Approved by Architecture Review Board. Approved version number set to 2.0 |
| 2009-08-19 | Updated to address all ITSC feedback. Endorsed by IT Standards Council |
| 2009-08-12 | Updated to address ITS feedback received August 7, 2009 |
| 2009-07-20 | Updated to reflect response to ITS feedback received July 14, 2009 |
| 2009-07-08 | Updated to reflect IT Standards Council (ITSC) feedback received by June 30, 2009 |
| 2009-05-12 | Updated legacy Standard to replace Portable Guide focus, with enterprise requirements. Based upon ITIL V3 |
Infographic descriptions
Infographic 1: Problem Management Workflow
ePM process workflow:
Step 1 – Task: Problem Detection
Roles involved: Problem Management Liaison, Service Owner, Problem Coordinator, Problem Analyst
Input/Trigger: Input: Incident database, incident trend reports, service metrics reports, event data, patterns
Trigger: Release notifications, multiple incidents, major incidents
Description - Identify possible problem areas by analyzing incident data, problem data, operational data, release notes, knowledge database and capacity or availability reports
Output: Problem identified
Step 2 – Task: Problem Logging, Classification and Prioritization
Roles Involved: Service Owner, Problem Coordinator, Problem Analyst, Problem Manager
Input/Trigger: Problem Identified
Description: Log a problem record, including all relevant information and links to associated Incident, Change and Configuration Item records
Output: Logged, classified, prioritized, and assigned problem record
Step 3 – Task: Investigation & Diagnosis
Roles Involved: Problem Management Liaison, Service Owner, Problem Analyst
Input/Trigger: Logged Problem Record
Description: The PA uses standard problem analysis techniques to diagnose and validate root cause of the problem. Once root cause or a workaround is found, a Known Error record is created and the solution is implemented as required. If the solution (root cause or workaround) is accepted by the SO, the problem can be resolved; else, the investigation and diagnosis continues. If a decision is not to proceed, or if a permanent solution cannot be found, the problem is closed as unresolved. If support is required from other organizations, PML can assist with obtaining SME support, as required, within their organizations
Output: Identified root cause, workaround, or unresolved problem.
Step 4 – Task: Known Error Record
Roles Involved: Problem Analyst, Problem Coordinator, Problem Manager
Input/Trigger: Identified root cause, workaround, or unresolved problem
Description: As soon as a workaround or root cause has been identified, even if it is not a permanent solution, a Known Error record must be raised. If further incidents or problems are raised they can be identified and the service restored more quickly. A Known Error record should be logged for an accepted unresolved problem to ensure cycles are not wasted in diagnosing and attempting to resolve a known and accepted deficiency
Output: Known Error
Step 5 – Task: Resolution
Roles Involved: Service Owner, Problem Analyst
Input/Trigger: Identified root cause, workaround – Description: Implementation of the solution via the appropriate change process. If the solution is a workaround, the SO can decide if this is an acceptable permanent solution. If not, the process falls back to the investigation and diagnosis phase. If a permanent solution has been identified, the SO will determine whether sufficient cost justification exists to proceed with a permanent solution. If not, the problem will be closed as Deferred and related records updated as necessary
Output: Implemented solution to remove root cause or workaround or no further action.
Step 6 – Task: Closure
Roles Involved: Problem Coordinator, Problem Manager
Input/Trigger: Removed root cause, workaround, deferred problem
Description: The problem record is updated to reflect all activities carried out during problem investigation and resolution. The status of any related Known Error records should be updated to show that the resolution has been applied.
Output: Completed Problem Investigation
Step 7 – Task: Critical Problem Review
Roles Involved: Problem Management Liaison, Service Owner, Problem Analyst, Problem Coordinator, Problem Manager
Trigger: Completed Problem Investigation
Description: After every critical problem, a review should be conducted by the Problem Manager to identify any lessons learned or potential CSI initiatives.
Output: Completed Critical Problem Review
Infographic 2: Differentiation
Differentiation: Process, Procedure, Work Instruction:
Level 1 tasks are defined in a process. They specify what action must be taken and who is involved.
Level 2 tasks are defined in procedures which decompose each level 1 task into more granular operational tasks, and additionally, prescribe how the activity should be performed.
Level 3 tasks represent work instructions. They are further decomposition of procedure-level tasks which typically are defined to address any unique local requirements when performing a procedural task.
Footnotes
- footnote[1] Back to paragraph Extracted from ITIL V3, Service Operations
- footnote[2] Back to paragraph Extracted from ITIL V3, Service Operations
- footnote[3] Back to paragraph Source: Copyright 2003-2007. Ahead Technology Inc.
- footnote[4] Back to paragraph Source: Copyright 2003-2007 Ahead technology Inc.
- footnote[5] Back to paragraph Extracted from ITIL V3, Service Operations
- footnote[6] Back to paragraph Extracted from ITIL V3, Service Operations